TWON Citizen Lab #4 in Brussels: On Overcoming Polarization
The fourth and final TWON Citizen Lab took place in Brussels from 14 to 18 March 2026. Bringing together young leaders from various communities from all over Europe came together to discuss a digital and sovereign European future. The program was a mixture of input and discussion from our TWON researchers, impulses from external researchers and civil society organizations, reflexional workshops and a public evening event – all centered around tackling hate, misinformation and polarization in the age of AI and tech-oligarchs, while also addressing questions of digital sovereignty in times of growing geopolitical tensions.
Cosima Pfannschmidt opened the Citizen Lab by introducing the group to the TWON project, its goals, and its urgency. Prof. Dr. Damian Trilling from the University of Amsterdam initiated a critical conversation on the limits of current research on social media dynamics, challenging assumptions about echo chambers, filter bubbles, and the spread of disinformation.
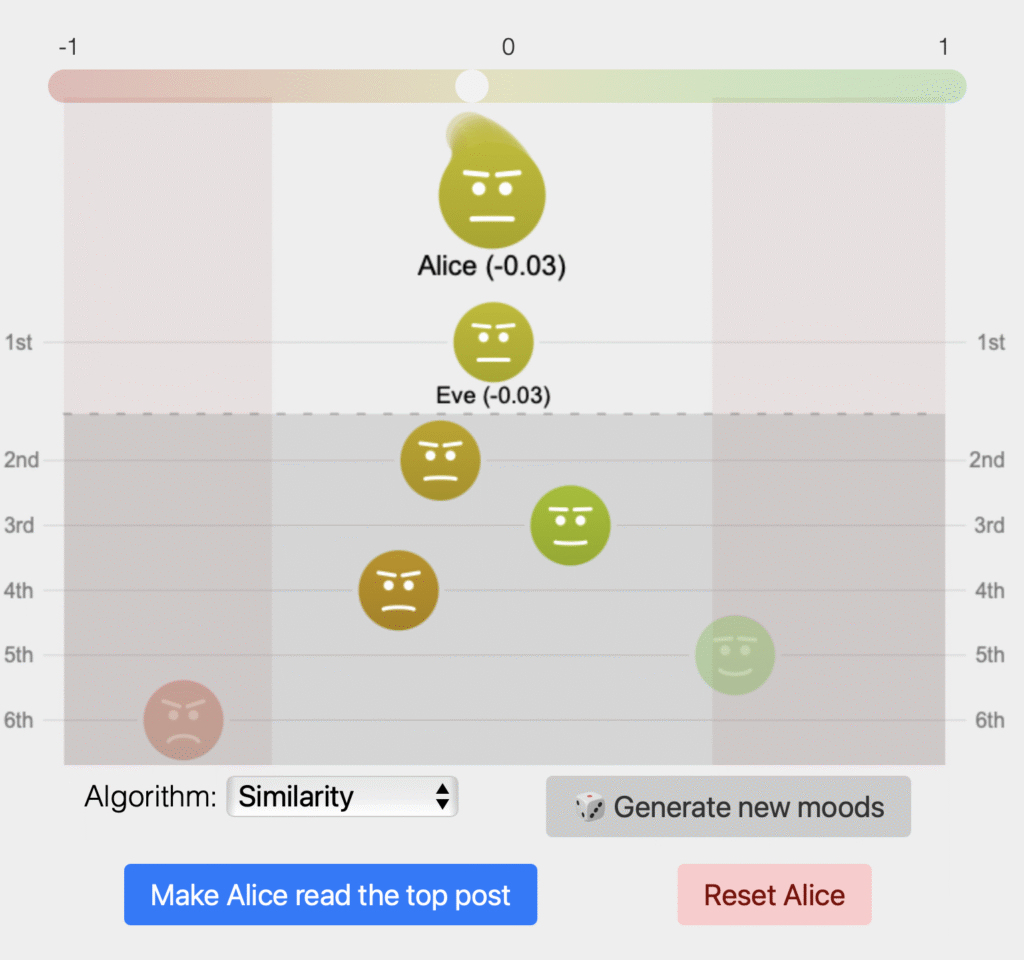
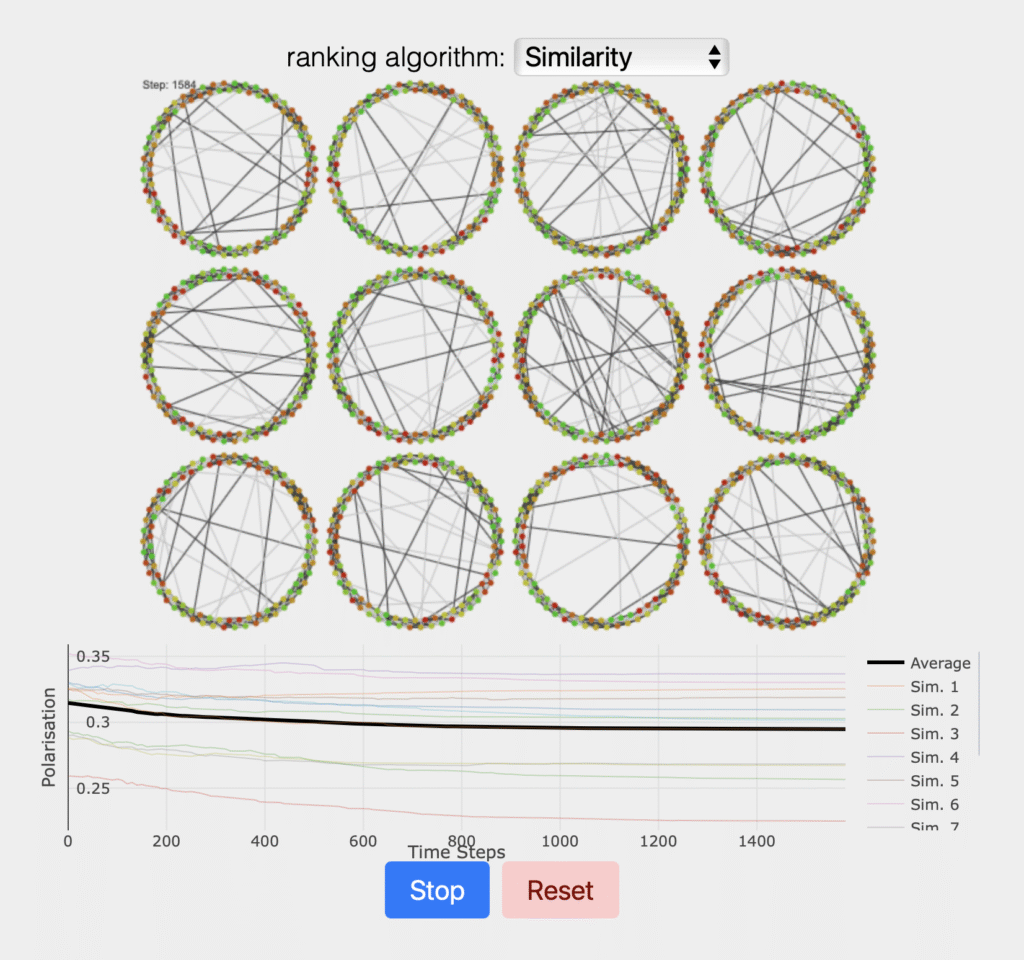
Simon Münker and Christoph Hau from Trier University, presented the TWON demonstrators, giving participants the opportunity to test out the TWONy simulations. Prof. Dr. Achim Rettinger from Trier University further addressed the complex intersection of AI agents and online discourse.
At the public evening event, the results of three years of TWON research were presented, with a deeper focus on digital sovereignty and the role of research in shaping evidence-based platform governance. In the first panel, moderated by Cosima Pfannschmidt (FZI), Prof. Achim Rettinger (Trier University), Michael Mäs (KIT), and François t’Serstevens (University of Amsterdam) presented TWON’s core ideas, key findings, and policy recommendations. In the second panel, moderated by Benjamin Fischer (CeMAS and Bellycat), Dr. Jonas Fegert (FZI), Katarina Barley (Vice President of the European Parliament) and Raegan MacDonald (Aspiration) discussed how research and policy can jointly shape Europe’s digital future and which steps can be taken to strengthen Europe’s digital sovereignty.
Beyond this the Citizen Lab included fantastic inputs from external researchers and civil society organizations:
Community Work in Conflict and Post-Conflict Settings: Experiences from Eastern Europe (Focus on Ukraine) with Igor Mitchnik (Executive Director Austausch e.V.)
How Polarisation Works: Recognising and Interpreting Political Narratives with (Atahan Demirel, Policy Advisor on Anti-Discrimination in the Berlin House of Representatives)
Invoking the Past, Legitimising the Present: The Use of Collective Memory in Digital Diplomacy with Maximiliane Linde (Researcher at FZI and Former Board Member of DialoguePerspectives e.V.)
Historicising the Present: Antisemitism and Racism in Israel-Palestine Social Media Discourses with Furkan Yüksel (Lecturer in Historical-Political Education)
Public Event “Voices Rising: Rebuilding Bridges. Dialogue, Trust and Solidarity Post-October 7th with Camila Piastro (European Union of Jewish Students) Barbara von Freytag (Journalist, Political Analyst) Furkan Yüksel (Political Educator)Prof. Dr. Achim Rettinger (Trier University, TWON) Moderation: Igor Mitchnik (Executive Director, Austausch e.V.)
Together Instead of Against Each Other: An Attempt to a Differentiated Dialogue on the Israeli-Palestinian conflict (A German Perspective) with Sophie Orentlikher (Socio-Political Educator and Clinical Social Worker, Centre for Applied Research on Education and Diversity at the Catholic College of Aachen) and Mohammed-Arfan Ashmawi (Social Educator and Clinical Social Worker, Research Assistant at the Centre for Applied Research on Education and Diversity at the Catholic College of Aachen)
Media Literacy in a Digital World with Amie Liebowitz (Journalist, Broadcast Presenter and Media Consultant World Café
The Citizen Lab concluded with a strong call for greater EU sovereignty in the digital sphere. The policy proposals developed throughout the week emphasized the need to regulate algorithmic systems, increase transparency, and create digital environments that enable meaningful dialogue rather than polarization. The Brussels Citizen Lab 2026 reminded us that social media must be more effectively regulated and that existing legislation, such as the Digital Services Act, must be consistently implemented and reinforced. At the same time, it highlighted the importance of enabling citizens to better understand what happens behind algorithmic systems.
We are deeply grateful for the Brussels Citizen Lab 2026, hosted by the TWON partner DialoguePerspectives. It was an unforgettable gathering that brought together European leaders committed to shaping democratic digital spaces. A heartfelt thank you to DialoguePerspectives and to everyone who made this experience so meaningful. It was an honor to be part of a space where listening, questioning, and reimagining Europe is not only possible but already happening.
A truly meaningful final Citizen Lab and a worthy farewell.